CSAPP: Network Programming
2024. 5. 7. 12:28ㆍ크래프톤 정글 5기/공부
1. Client - Server Programming Model
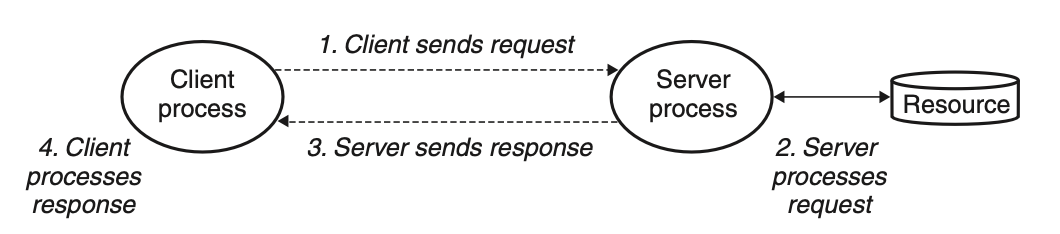
- 모든 네트워크 Application : Client - Server Model
→ 1개의 Server ↔ 1개의 Client- 서버
: 일부 리소스 관리 / 조작 → 클라이언트에 서비스 제공
ex) 웹서버 , FTP 서버, 이메일 서버
웹서버 : 디스크 파일 관리 -> 클라이언트를 대신해 이들을 가져오고 실행
FTP 서버 : 클라이언트를 위해 저장하고 읽어오는 디스크 파일 관리
이메일 서버 : 클라이언트를 위해 읽고 갱신하는 스풀 파일 관리Client - Server Model의 근본적 연산 = Transaction
* Transaction : DB의 상태를 변화시키기 위해 수행하는 작업의 단위
DB의 상태 변화 : SELECT, INSERT, DELETE, UPDATE
Transaction Properties :
1. 원자성 (Atomicity)
Transaction 실행 도중 문제가 발생한 경우, 모두 실패 혹은 모두 성공 상태가 되어야 한다
=> 100개 중 99개 성공 == 100개 중 0개 성공 (성공이 아니면 모두 실패 처리)
==> 중간 상태가 없다
2. 일관성 (Consistency)
Transaction 완료 후에도 DB가 일관된 상태로 유지되어야 함
3. 고립성 (Isolation)
하나의 Transaction이 실행하는 도중 변경한 데이터는 / 해당 Transaction 완료까지 다른
Transaction이 참조하지 못함
4. 지속성 (Durability)
Transaction이 성공적으로 완료된다 -> 결과는 영구적으로 반영되어야 한다
Commit & Rollback
Commit : 하나의 Transaction이 성공적으로 완료 -> DB가 일관성 있는 상태에 있을 때
하나의 Transaction이 끝났다는 것을 알려주기 위해 사용하는 연산
=> 수행한 Transaction이 로그에 저장
Rollback : 하나의 Transaction이 비정상적으로 종료 -> 원자성이 위배된 경우
Transaction을 다시 시작 or 부분적으로 연산 결과 취소
==> Transaction은 데이터의 완전성을 보장하기 위해 많은 resources 사용
-> 많은 자원을 소모한 채 대기하는 시간이 많아지면 성능에 악영향
--> Transaction의 범위를 최소화하는 것이 좋다
2. Network

- 클라이언트와 서버는 프로세스 / not host or machine
→ 1개의 host : 서로 다른 많은 클리어인트와 서버 동시 실행 가능
—> 클라이언트와 서버는 동일하거나 다른 호스트에 존재 가능
- Network는 복잡한 시스템 / 호스트에게 Network는 단지 또 다른 I/O 디바이스
- Network adapter : Network에 물리적인 인터페이스 제공
- 네트워크에서 수신한 데이터 → Adapter → Memory (usually DMA)
- 메모리에서 복사한 데이터 → Adapter → Network

- 이더넷 세그먼트 :
몇 개의 전선들과 허브라고 부르는 작은 상자로 구성
각 전선은 동일한 최대 비트 대역폭 가짐 (100Mb/s, 1Gb/s)
한쪽 끝은 호스트의 어댑터에 연결 / 다른 끝은 허브의 포트에 연결
- 이더넷 어댑터 :
어댑터의 비휘발성 메모리에 저장된 전체적으로 고유한 48비트 주소 가짐
- 호스트 :
호스트는 프레임이라고 부르는 비트를 세그먼트의 다른 호스트에 보냄
각 프레임은 [프레임의 소스, 목적지, 프레임 길이 식별용 고정 헤더 비트, 데이터 비트] 로 구성
목적지 호스트만이 프레임을 읽는다
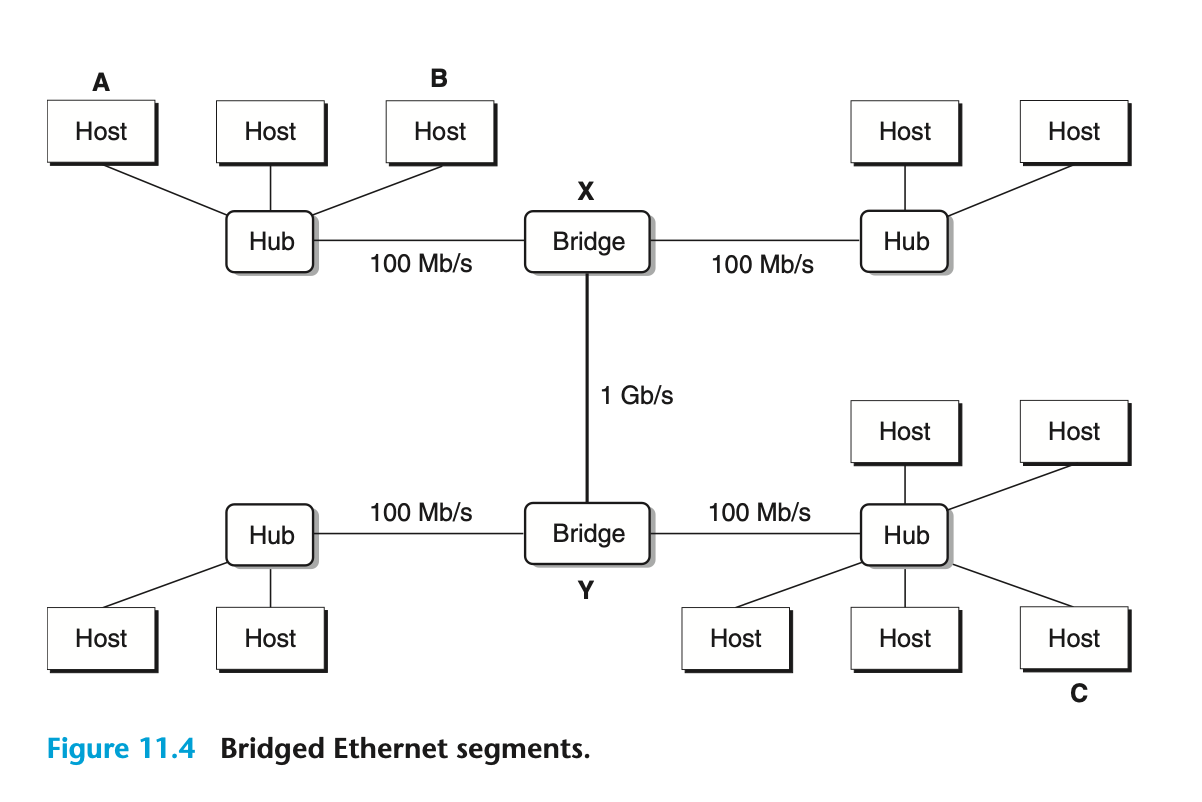
전선들과 Bridge라는 작은 상자를 이용하여 다수의 이더넷 세그먼트를 연결 ⇒ 브릿지형 이더넷
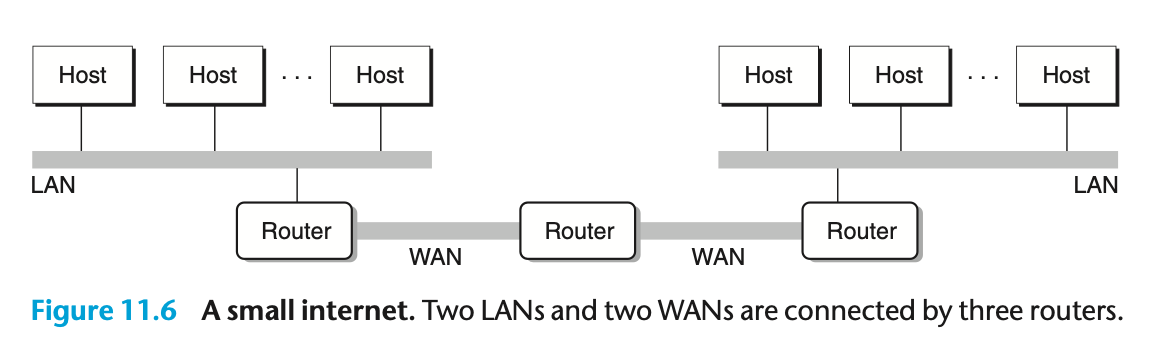
- 그림은 3개의 라우터로 연결된 LAN/WAN 쌍을 갖는 Internet
- 계층구조의 상부에서 다수의 비호환성 LAN들을 *Router* 라는 특별한 컴퓨터로 연결
- Router :
네트워크 간 연결 구성 (상호연결 네트워크)
각 네트워크에 대한 어댑터(포트) 가지고 있음
⇒ LAN, WAN으로부터 Internet을 만들기 위해 사용된다
How it is possible for some source host to send data bits to another destination host across all of these incompatible networks ?
→ 다른 네트워크 간의 차이를 줄여 주는 / 각 호스트와 라우터에서 돌고 있는 / 프로토콜 소프트웨어 계층
⇒ 호스트와 라우터가 데이터 전송을 위해 어떻게 작동하는지 결정하는 프로토콜
프로토콜 소프트웨어 계층의 2가지 기본 기능
1. 명명법 (Naming Scheme)
서로 다른 LAN은 주소를 호스트에게 할당하는 서로 다른 비호환성을 갖는 방법을 사용
internet Protocol : 호스트 주소를 위한 통일된 포맷 정의 -> 차이점 줄인다
--> 각 호스트는 자신의 고유 식별 번호인 internet address 1개가 할당된다
2. 전달기법 (Delivery mechanism)
서로 다른 네트워킹 기술은 / 서로 다른 비호환성을 갖는 비트 인코딩 방법과 / 이를 프레임 내에 패키징
하는 방법을 갖는다
inter Protocol : 데이터 비트를 패킷이라고 부르는 비연속적인 단위로 묶는 통일된 방법 정의
-> 차이점 줄인다
Packet : 패킷 크기 / 소스 / 목적지 호스트 주소를 포함하는 헤더 + 소스 호스트가 보낸 데이터 비트
# 호스트 A -> 호스트 B 데이터 전송 과정
1. Host A의 Client : Client의 가상 주소공간에서 커널 버퍼로 데이터 복사 시스템 콜 호출
2. Host A의 Protocol SW : [internet header + LAN1 Frame header] 데이터에 추가
-> [LAN1 프레임] 생성 (프레임 데이터 == internet 패킷)
(internet header : Host B 주소) (= Packet header)
(LAN1 Frame header : 라우터 주소)
Host A는 이 LAN1 프레임을 어댑터에 전달
3. LAN1 어댑터는 이 프레임을 네트워크로 복사
4. 프레임이 라우터에 도달 -> 라우터의 LAN1 어댑터는 전선에서 이것을 읽어서 Protocol SW로 전달
5. 라우터는 [internet header]에서 목적지 (Host B) 주소를 가져온 뒤 LAN2 라우팅 테이블에서의 인덱스로 사용
라우터는 [LAN1 Frame header](= Router address)를 벗겨내고, Host B address를 갖는 LAN2 Frame Header로 갈아끼운다
라우터는 이 프로세스를 모두 수행한 뒤, LAN2 어댑터로 전달한다
6. 라우터의 LAN2 어댑터는 이 프레임을 네트워크로 복사한다
7. 프레임이 Host B에 도차하면 어댑터는 이 프레임을 전선에서 읽고, Protocol SW에 넘긴다
8. Protocol SW는 Packet Header, Frame Header를 벗겨낸다
Protocol SW는 해당 데이터를 / 서버가 [데이터를 읽는 시스템콜] 호출 때 / 서버의 가상 주소공간으로 복사
3. Global IP Internet
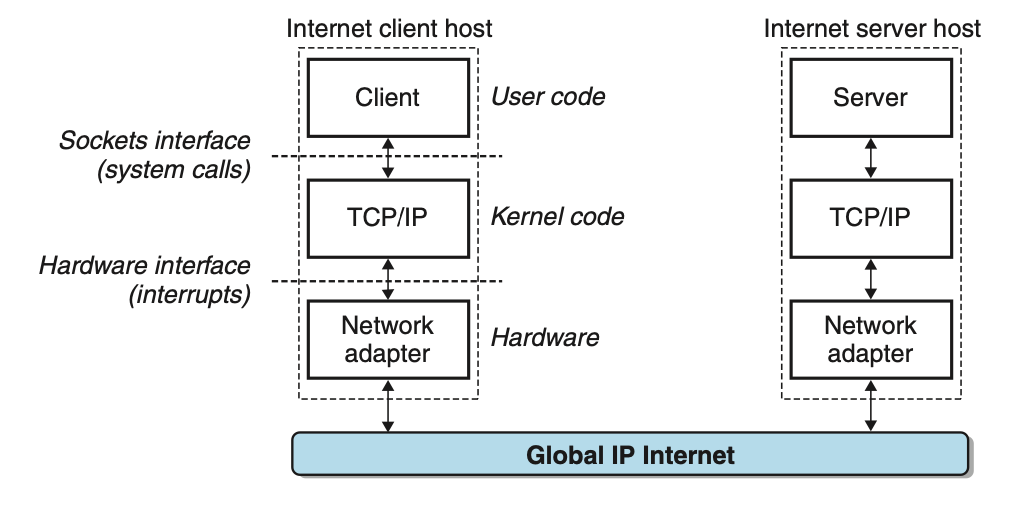
- 인터넷은 지속적으로 바뀌고 있지만, Client - Server 응용 구조는 안정적으로 지속되는 중
- 각 인터넷 호스트는 TCP/IP Protocol 구현한 SW 실행
 |
 |
* Protocol
Definition :
컴퓨터 네트워크에서 통신을 위한 규칙의 집합
통신 기기 사이에 데이터를 주고받는 방법을 정의 [데이터의 형식, 전송 방법 오류 검출 및 수정 방법]
일반적으로 TCP/IP Protocol 사용
(HTTP, FTP, SMTP)* TCP/IP Protocol (Transmission Control Protocol / Internet Protocol)
- IP Protocol :
프로토콜 중 하나 / IP 주소 체계, 데이터그램 포맷, 패킷 라우팅을 위한 규칙 포함
1. IP 주소
컴퓨터 또는 네트워크 장치를 식별하기 위한 고유한 숫자
IPv4 주소는 32비트로 구성
IPv6 주소는 128비트로 구성
2. 데이터그램 포맷
IP는 데이터그램을 사용해 정보를 전송 (Datagram = 작은 데이터 패킷)
각 데이터그램에는 출발지 및 목적지 IP 주소 포함
3. 패킷 라우팅
IP는 패킷의 출발지에서 목적지로의 경로를 결정하는 역할
라우터는 IP 주소를 기반으로 패킷을 전달하고 네트워크의 경로를 통해 패킷을 전송
4. 서비스 타입
IP 헤더에는 서비스 타입 필드가 포함 (패킷의 우선 순위)
-> 다양한 트래픽 유형에 대해 서로 다른 서비스 품질 제공
5. 버전 및 옵션
IP 헤더에는 프로토콜 버전 및 추가적인 옵션 정보 포함
=> 대규모 네트워크에서 데이터 통신을 지원 / 네트워크 안정성 및 효율성 유지
- TCP Protocol :
프로토콜 중 하나 / IP와 함께 사용되며, 신뢰성 있고 순차대로 데이터를 전송
-> 데이터 손실 및 손상의 가능성 감소 / 데이터의 정확성 보장
1. 연결 지향성
TCP는 연결 지향 프로토콜
데이터를 전송하기 전에 먼저 연결 설정 / 데이터 모두 전송 후 연결 해제
데이터 전달 여부 확인을 위해 Handshake Process 사용
2. 신뢰성
TCP는 데이터 전송 중 발생 가능성이 있는 손실, 중복, 순서 오류 등의 문제 처리
각 데이터의 작은 조각 (세그먼트)에 일련 번호 할당
수신 측에서는 이를 사용해 데이터의 순서 확인 및 응답
3. 흐름 제어
TCP는 송신자와 수신자 간의 데이터 흐름을 조절하는 메카니즘 제공
송신 측 네트워크 혼잡 상황 & 수신 측 데이터 처리 가능 용량을 이용해 혼잡 방지 및 효율적 전송 유지
4. 혼잡 제어
TCP는 네트워크 혼잡을 관리하기 위한 메커니즘 제공
네트워크 혼잡 상황이 발생 -> 전송 속도를 줄임 -> 혼잡 해소 -> 전송 속도 증가
5. 전이중 및 전이중 통신
TCP는 전이중 및 전이중 통신 지원
[전이중 통신 = 송신자와 수신자가 동시에 데이터를 전송 및 수신하는 기능]- IP 프로토콜은 패킷 전달 여부를 보증하지 않는다
- IP 프로토콜은 패킷 송신 순서와 수신 순서를 보증하지 않는다
- TCP 프로토콜은 데이터의 전달을 보증한다
- TCP 프로토콜은 데이터의 송신 순서와 수신 순서를 보증한다
-> 두 개의 프로토콜을 적절히 섞어서 쓰겠다 => TCP/IP Protocol
** IP 특성을 활용해 / IP 주소 체계를 따르고 / IP routing을 통해 목적지에 도달하겠다
** TCP 특성을 활용해 / 송신자와 수신자의 논리적 연결을 생성하고 / 신뢰성을 유지하겠다
==> 송신자가 수신자에게 IP 주소를 사용하여 데이터를 전달하고, 목적지에 도착할 때 까지 관리하겠다
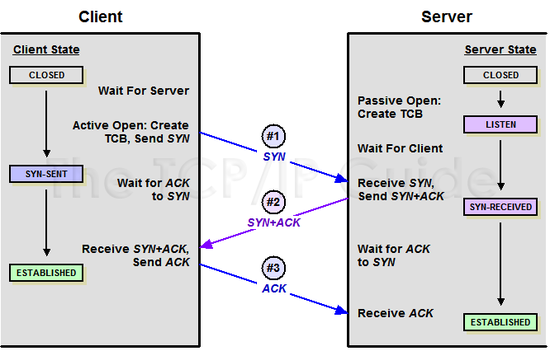
** TCP 3 way Handshake
- 신뢰성 있는 연결을 설정하기 위해 사용되는 프로세스
- 클라이언트 - 서버 연결을 설정하고 동기화하는 과정
1. SYN (Synchronize Sequence Number)
클라이언트는 서버에 SYN 세그먼트를 보내 연결을 요청하는 단계
SYN 플래그를 1로 설정한 세그먼트를 서버에 전송
SYN 패킷에는 클라이언트의 초기 시퀀스 번호 (ISN, Initial Sequence Number) 포함
2. SYN-ACK (Acknowledgment)
서버가 클라이언트의 연결 요청을 수락하고 응답하는 단계
서버는 SYN 플래그와 ACK 플래그를 1로 설정한 세그먼트를 클라이언트에 전송
세그먼트에는 서버의 ISN과 클라이언트의 ISN + 1이 포함됨
서버의 ISN은 서버가 생성한 고유 시퀀스 넘버
클라이언트의 ISN + 1 = 클라이언트의 SYN 세그먼트를 서버가 잘 받았다는 의미
3. ACK
클라이언트가 서버의 응답을 받고 최종 확인하는 단계
클라이언트는 ACK 플래그를 1로 설정한 세그먼트를 서버에 전송
세그먼트에는 서버의 ISN + 1 = 서버의 SYN-ACK 세그먼트를 잘 받았다는 의미
3.1 IP Address
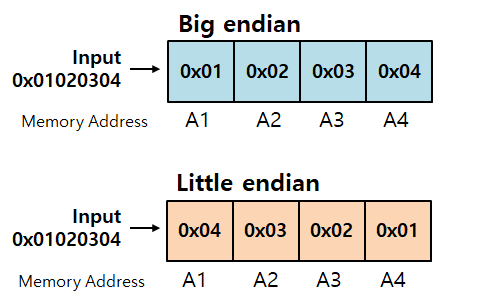
> 저장할 때 상위 바이트. 즉, 큰 쪽을 먼저 저장하는 것을 빅 엔디안(Big Endian)
> 저장할 때 하위 바이트. 즉, 작은 쪽을 먼저 저장하는 것을 리틀 엔디안(Little Endian)
- IP 주소 : 비부호형 32비트 정수
- 인터넷 호스트들 마다 순서가 다르면 문제가 생길 수 있음 (Big Endian → Little Endian)
- 이러한 문제 발생 방지를 위해 IP주소와 같은 모든 정수형 데이터는 통일된 네트워크 바이트 순서 가짐
(= Big endian)
- 네트워크와 호스트 바이트 순서 간의 변환을 위한 함수가 존재한다
- IP는 십진수 값을 사용하고 점을 사용해서 구분하는 *Dotted-decimal* 표기로 제시된다
리눅스에서는 {hostname -i} 명령을 통해 dotted-decimal 주소 결정 가능
3.2 Inter Domain Name
- 클라이언트 - 서버 간 통신에는 IP 주소가 사용된다
- IP 주소로 특정 페이지에 접근하는 건 힘든 일 → 도메인 이름들의 집합을 IP 주소 집합으로 매핑
⇒ 도메인 이름 집합
- 도메인 이름 집합은 계층구조를 형성
- DNS(Domain Name System) 이라고 하는 데이터베이스에 의해 Domain 관리
- 리눅스의 nslookup 명령어로 DNS 매핑의 일부 특성들을 조사할 수 있다
3.3 Internet Connection
- Client - Server 관계는 연결을 통해 바이트 스트림을 주고받는 방식
- 두개의 프로세스를 연결한다 → point to point 연결
- 동시에 양방향으로 흐른다 → full-duplex
- 소스 프로세스가 보낸 바이트 스트림은 순서를 유지하며 목적지 프로세스로 전달된다* Socket :
네트워크 통신에서 사용되는 API / 프로세스 간 통신 가능케 함
소켓 사용으로, 네트워크를 통해 데이터를 주고받음
TCP/IP와 같은 프로토콜을 사용하여 통신 처리
OS 커널에 구현되어 있는 프로토콜 요소에 대한 추상화된 인터페이스
장치 파일의 일종
Properties :
1. 통신 종단점
소켓은 통신에 참여하는 프로세스의 종단점
각 소켓은 고유한 주소와 포트 번호를 가지며, 이를 통해 특정 프로세스를 식별하고 통신을 수행
2. 네트워크 프로토콜과의 상호 작용
소켓은 네트워크 프로토콜과 상호 작용하여 데이터를 전송하고 수신
3. 클라이언트 및 서버 역할
소켓은 클라이언트 및 서버 간 통신을 지원
Client Socket : 서버에 연결하여 데이터 요청
Server Socket : 클라이언트 요청을 수신하고 처리
4. 다중 연결
하나의 응용 프로그램은 여러 개의 소켓을 생성하여 동시에 연결 처리 가능
-> 다중 클라이언트와의 동시 통신 지원
5. 프로세스 간 통신
프로세스 간 통신을 가능하게 함 => IPC ?
4. Socket Interface
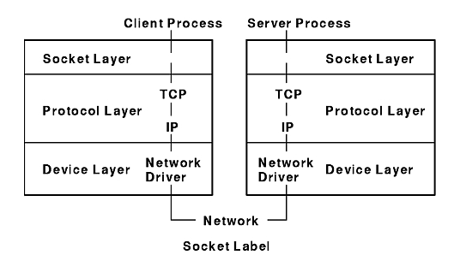
- 논리적인 의미로 컴퓨터 네트워크를 경유하는 IPC의 종착점
- 네트워크를 이용해 데이터를 송수신하고자 한다면 소켓을 거쳐야 함
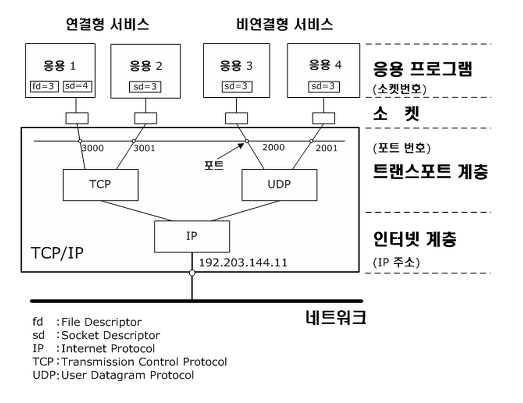
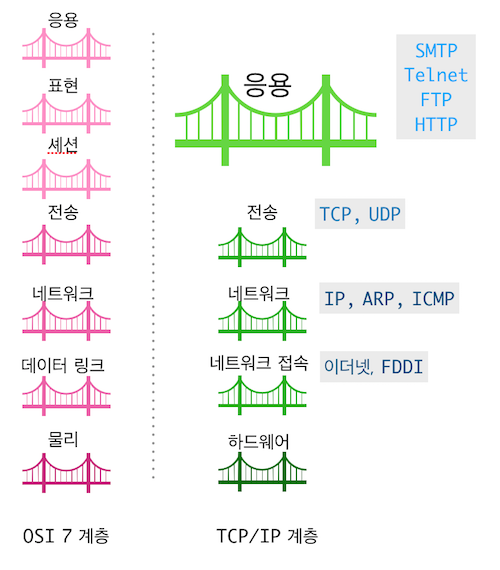
- OSI 7 계층의 어플리케이션 계층에 존재하는 네트워크 응용 프로그램은
- 데이터를 송수신하기 위해 소켓을 거쳐 전송계층의 통신망으로 전달
- 소켓은 [응용 프로그램 ↔ 전송계층] 사이에 위치 / 응용프로그램을 위한 인터페이스 역할
# 통신을 통해 전달되는 모든 데이터 포맷 -> 5 Tuple 규격
1. 프로토콜
데이터 송수신 방법 정의
2. 호스트 IP 주소 (호스트 구별)
송신 호스트 식별자
3. 호스트 Port 번호 (프로세스 식별)
송신 호스트 프로세스 식별자
4. 목적지 IP 주소
수신 호스트 식별자
5. 목적지 Port 번호
수신 호스트 프로세스 식별자Properties of Socket
1. Client - server
TCP/UDP (전달 계층) 위에서 동작하므로 client-server 구조 갖는다
데이터 송신 : Client / 데이터 수신 : Server
2. 양방향 통신
Socket은 한 쪽에서 데이터를 보내고 반대 편에서 이를 수신한 뒤 연결이 끊기지 않음
양 쪽에서 실시간으로 데이터 송수신 가능
3. 종속적
Socket은 프로토콜 종류가 아닌 / Network Programming Interface
OS마다, 프로그래밍 언어마다 소켓 라이브러리가 다르다

- 소켓 주소 표현 구조체
struct sockaddr {
sa_family_t sa_family; # 주소 체계 나타내는 상수값 (IPv4 / IPv6)
char sa_data[14]; # 실제 주소 정보 담는 배열
}
- 프로토콜 별로 세부적인 주소 정보 다루기 위해 확장한 구조체 사용
struct sockaddr_in {
sa_family_t sin_family; # 주소 체계 (IPv4 / IPv6) / 2바이트
in_port_t sin_port; # 포트 번호 / 2바이트
struct in_addr sin_addr; # IPv4, IPv6 주소 / 4바이트
char sin_zero[8] # 패딩을 위한 빈 공간 / 8바이트
}
struct in_addr {
unit32_t s_addr; # 32 비트 IPv4 주소
}
- sockaddr_in 구조체를 만들어 주소 정보 설정
struct sockaddr_in addr;
memset(&addr, 0, sizeof(addr));
addr.sin_family = AF_INET;
addr.sin_port = htons(PORT);
addr.sin_addr.s_addr = inet_addr("127.0.0.1");
memset() : 구조체 0으로 초기화
sin_family : sin_family 필드를 AF_INET으로 설정 == IPv4 주소 체계 설정
sin_port : sin_port 필드를 원하는 포트 번호로 설정
htons() : 호스트 바이트 순서를 네트워크 바이트 순서로 변환
sin_addr.s_addr : sin_addr 필드의 s_addr 필드를 원하는 IP 주소로 설정
inet_addr : 점으로 구분된 문자열 형태의 IP주소를 32비트 정수로 변환* sockaddr_in / sockaddr의 차이점
sockaddr_in은 IPv4 주소 정보를 저장하기 위해 특별히 정의된 구조체
sockaddr은 일반적인 주소 정보를 저장하기 위한 구조체
sockaddr_in, sockaddr 구조체 모두 [주소 체계를 포함하며, 16바이트] 동일한 메모리 레이아웃 가짐
하지만 소켓 인터페이스 함수에서는 입력 인자로 sockaddr 포인터를 입력받는다
sockaddr_in 구조체를 사용하기 위해, 굳이 (struct sockaddr *) 방식으로 타입 캐스팅을 진행
-> 왜 입력인자로 sockaddr_in 구조체를 바로 넣지 않나 ?
1. 주소 체계의 독립성
-> 소켓 인터페이스 함수는 다양한 주소 체계 (IPv4, IPv6)을 지원하도록 설계
함수는 특정한 주소 체계에 종속되지 않고 일반화한 형태로 동작
=> 코드의 유연성과 확장성이 높아진다
2. 코드의 일관성
-> 모든 인터페이스 함수들이 sockaddr 구조체 포인터를 사용하도록 통일
=> 코드 이해 및 유지보수에 이점
3. 다른 주소 체계로의 확장성
-> 통일된 구조체 포인터를 사용하면, 다른 주소 체계로 확장하기 쉽다
4. Historical reason
-> 초기 소켓 API 설계 당시에는 다양한 주소 체계를 고려하여 일반화한 형태로 설계
이러한 관례를 유지하기 위해 인터페이스 함수 입력 인자를 sockaddr로 진행하는 것
- 서버 측 Method
1. socket() :
int socket(int domain, int type, int protocol);
domain : 프로토콜 패밀리 지정 / AF_INET : IPv4 / AF_INET6 : IPv6
type : 소켓 타입 지정 / SOCK_STREAM : TCP / SOCK_DGRAM : UDP
protocol : 프로토콜 지정(0 == 기본 프로토콜)
=> sockfd = Socket(AF_INET, SOCK_STREAM, 0);
==> 성공 시 소켓 디스크립터 반환 (소켓 식별자)
2. bind() :
int bind(int sockfd, const struct sockaddr *addr, socklen_t addrlen);
sockfd : 소켓 디스크립터 지정
addr : 소켓에 할당할 주소 정보를 담은 sockaddr 구조체 포인터 지정
addrlen : addr 인자로 전달된 주소 구조체의 크기 지정
=> 지정된 소켓 디스크립터에 주소 정보를 할당 / 소켓을 특정 IP 주소와 포트 번호에 바인딩
3. listen() :
int listen(int sockfd, int backlog);
sockfd : 소켓 디스크립터 지정
backlog : 연결 요청 대기열의 최대 길이 지정 (보통 1024 같은 큰 값 지정)
=> 지정된 소켓을 수동 대기 모드로 전환하여 클라이언트의 연결 요청 받을 준비
4. accept() :
int accept(int sockfd, struct sockaddr *addr, socklen_t *addrlen);
sockfd : 소켓 디스크립터 지정
addr : 연결된 클라이언트의 주소 정보를 저장할 sockaddr 구조체 포인터 지정
addrlen : addr 인자로 전달된 주소 구조체의 크기를 저장할 변수의 포인터 지정
=> 클라이언트의 연결 요청 수락, 새로운 소켓 디스크립터 반환 -> 클라이언트와의 통신에 사용
5. send(), recv() :
ssize_t send(int sockfd, const void *buf, size_t len, int flags);
ssize_t recv(int sockfd, void *buf, size_t len, int flags);
sockfd : 소켓 디스크립터 지정
buf : 전송할 데이터의 버퍼 포인터 또는 수신한 데이터를 저장할 버퍼 포인터 지정
len : 전송할 데이터의 크기 또는 수신할 데이터의 최대 크기 지정
flags : 전송 또는 수신 동작을 제어하는 플래그 지정 / 일반적으로 0 사용
=> send() : 지정된 소켓을 통해 데이터 전송 / recv() : 저장된 소켓에서 데이터 수신
6. close() :
int close(int sockfd);
sockfd : 소켓 디스크립터를 지정
=> 지정된 소켓 디스크립터를 닫고 자원을 해제
- Client 측 Method
1. socket() :
int socket(int domain, int type, int protocol);
서버 측과 동일
2. connect() :
int connect(int sockfd, const struct sockaddr *addr, socklen_t addrlen);
sockfd : 소켓 디스크립터 지정
addr : 연결할 서버의 주소 정보를 담은 sockaddr 구조체 포인터 지정
addrlen : addr 인자로 전달된 주소 구조체의 크기 지정
3. send(), recv() :
ssize_send(int sockfd, const void *buf, size_t len, int flags);
ssize_recv(int sockfd, void *buf, size_t len, int flags);
서버 측과 동일
4. close() :
int close(int sockfd);
서버 측과 동일
# getaddrinfo / getnameinfo
1. getaddrinfo()
struct addrinfo hints, *result;
int getaddrinfo(const char *node, const char *service, const struct addrinfo *hints,
struct addrinfo **result);
node : 호스트 이름 또는 IP 주소를 나타내는 문자열 포인터
service : 서비스 이름 또는 포트 번호를 나타내는 문자열 포인터
hints : 주소 정보 검색 조건을 저장하는 addrinfo 구조체 포인터
result : 검색 결과로 얻은 주소 정보 리스트의 포인터를 저장할 addrinfo 구조체 이중 포인터
=> 호스트 이름 또는 IP 주소와 서비스 이름 또는 포트 번호를 기반으로 주소 정보 검색 / 검색 결과를 반환
2. getnameinfo()
int getnameinfo(const struct sockaddr *sa, socklen_t salen, char *host, size_t hostlen,
char *serv, size_t servlen, int flags)
sa : 주소 정보를 담고 있는 sockaddr 구조체 포인터
salen : sa 인자로 전달된 주소 구조체의 크기
host : 호스트 이름을 저장할 버퍼의 포인터
hostlen : host 버퍼의 크기
serv : 서비스 이름을 저장할 버퍼의 포인터
servlen : serv 버퍼의 크기
flags : 주소 변환 옵션을 지정하는 플래그
=> 주소정보(sockaddr 구조체)를 기반으로 호스트 이름과 서비스 이름을 검색 -> 검색 결과 host, serv 버퍼에 저장
3. freeaddrinfo()
void freeaddrinfo(struct addrinfo *res)
res : 해제할 주소 정보 리스트의 포인터
getaddrinfo()의 리턴값
=> 입력된 주소 정보 리스트의 모든 메모리가 해제
*getaddrinfo : 호스트 이름과 서비스 이름을 기반으로 주소 정보 검색 시 사용
프로토콜에 독립적인 방식으로 주소 정보 검색
반환된 주소 정보 리스트는 freeaddrinfo 함수 사용하여 해제 해야 함
*getnameinfo : 주소 정보를 기반으로 호스트 이름과 서비스 이름 검색 시 사용
sockaddr 구조체를 인자로 받아 해당 주소에 해당하는 호스트 이름과 서비스 이름 반환- getaddrinfo() 호출 시 무엇이 리턴되는가 ?
호스트 이름과 서비스 이름을 기반으로 주소 정보를 조회
해당 주소 정보를 담고 있는 addrinfo 구조체의 연결 리스트 생성
struct addrinfo {
int ai_flags; # 추가 옵션 플래그
int ai_family; # 주소 체계 (AF_INET, AF_INET6 등)
int ai_socktype; # 소켓 타입 (SOCK_STREAM, SOCK_DGRAM) == (TCP, UDP)
int ai_protocol; # 프로토콜 (0은 기본값)
soclen_t ai_addlen; # ai_addr 필드의 크기
struct sockaddr *ai_addr; # 소켓 주소 구조체 포인터
char *ai_canonname; # 정규화된 호스트 이름
struct addrinfo *ai_next; # 다음 addrinfo 구조체를 가리키는 포인터
}
- getnameinfo() 호출 시 어떻게 동작하는가 ?
소켓 구조체(sockaddr)에서 호스트 이름과 서비스 이름(포트 번호)를 추출
client, server buffer에 추출한 정보를 저장
client - server 통신 연결 이후 수행하는 메소드
# C library
1. getenv()
환경 변수를 가져오는 데 사용
환경 변수 : 운영 체제나 쉘에서 설정되는 변수, 프로세스에 추가 정보 제공
char *getenv(const char *name);
name : 값을 가져올 환경 변수의 이름을 나타내는 문자열 포인터
-> 환경 변수의 값을 가리키는 문자열 포인터 반환
* 호출 시 전달된 환경 변수 이름 검색
해당 환경 변수의 값 반환
2. strcpy()
한 문자열을 다른 문자열로 복사하는 데 사용
char *strcpy(char *dest, const char *src);
dest : 복사 대상 문자열을 가리키는 포인터
src : 복사할 원본 문자열을 가리키는 포인터
-> 복사 이후 dest 포인터 반환
* src가 가리키는 문자열을 dest가 가리키는 위치로 복사
src의 널 문자('\0')까지 복사
dest에는 충분한 공간이 할당되어 있어야 함
3. atoi()
문자열을 정수로 변환하는 데 사용
int atoi(const char *str);
str : 변환할 문자열을 가리키는 포인터
-> 변환된 정수 값 반환
* str이 가리키는 문자열을 정수로 변환
문자열을 선행 공백을 무시 / 첫 번째 문자부터 변환 시작
4. strchr()
문자열에서 지정된 문자를 찾아 해당 문자의 위치를 가리키는 포인터 반환
char *strchr(const char *str, int c);
str : 검색할 문자열 가리키는 포인터
c : 찾을 문자 (int로 전달 -> 내부에서는 unsigned char로 변환)
-> 문자열에서 찾은 문자의 위치를 가리키는 포인터 반환
문자열의 시작부터 순차적으로 검색 / 처음 일치하는 문자의 위치 포인터 반환
5. sprintf()
C언어 표준 라이브러리
형식화된 문자열을 버퍼에 씀
출력을 화면에 하지 않고, 지정된 버퍼에 저장
int sprintf(char *str, const char *format, ...)
str : 형식화된 문자열을 저장한 버퍼의 포인터
format : 형식 문자열
... : 문자열에 따라 가변 인자로 전달되는 포인터
==> getenv() : 프로그램 실행 환경에서 설정된 환경 변수의 값 가져오는 데 사용
strcpy() : 문자열을 복사할 때 사요으 문자열 조작에 필수적 함수
atoi() : 문자열로 표현된 숫자를 정수로 변환하는 데 사용
** CGI (Common Gateway Interface)
Definition :
웹 서버와 외부 프로그램 간의 인터페이스를 정의하는 표준
외부 프로그램의 출력을 다시 클라이언트에게 전송 (클라이언트 - 외부 프로그램 - 서버)
-> 동적인 웹 콘텐츠를 생성
Reason :
1. 동적 프로그램 생성
CGI를 통해 웹 서버는 정적인 HTML 파일뿐만 아니라 실행 시점에 동적으로 생성된 콘텐츠 제공 가능
2. 사용자 상호작용
CGI 프로그램은 사용자의 입력을 받아 처리하고 결과를 반환할 수 있다
-> 웹 페이지에서 사용자와 상호작용 할 수 있다
3. 데이터베이스 연동
CGI 프로그램은 데이터베이스와 연동하여 데이터 저장, 조회, 수정 가능
-> 동적인 웹 어플리케이션 구축 가능
4. 서버 사이드 로직 처리
CGI 프로그램은 서버 측에서 복잡한 로직 처리 가능
-> 클라이언트의 부담을 줄이고 서버에서 중요한 작업 수행 가능
환경 변수 :
웹 서버가 CGI 프로그램에 전달하는 정보를 담고 있는 변수
-> CGI 프로그램이 request 상세 정보를 얻을 수 있게 함
1. QUERY_STRING
GET 요청의 쿼리 문자열 포함
ex) http://example.com/program.cgi?name=John&age=30
여기서의 QUERY_STRING : name=John&age=30
2. REQUEST_METHOD
HTTP 요청 method 나타냄 (GET, POST 등)
3. CONTENT_LENGTH
POST 요청의 메세지 본문 길이 나타냄
4. CONTENT_TYPE
POST 요청의 메시지 본문 타입 나타냄
5. REMOTE_ADDR
클라이언트의 IP 주소를 포함
6. SERVER_NAME
서버의 호스트 이름을 포함
7. SERVER_PORT
서버의 포트 번호 포함
'크래프톤 정글 5기 > 공부' 카테고리의 다른 글
| [PintOS] 1-1 Alarm Clock (0) | 2024.05.16 |
|---|---|
| [PintOS] Project 1 키워드 정리 (Race Condition, Context Switching, PCB, Process State) (0) | 2024.05.10 |
| [Webproxy-lab] Tiny Web Server (0) | 2024.05.06 |
| [Webproxy-lab] Echo server communication (0) | 2024.05.04 |
| System Call (+ OS, Kernel) (0) | 2024.05.01 |